
The U.S. government is one of the largest producers of data globally. Federal agencies are one of the biggest producers, analyzers, collectors, and distributors of data, ranging from weather forecasts to economic indicators to health statistics.
In an era where data is as valuable as currency, governments worldwide are turning to predictive AI models to anticipate and address the multifaceted needs of the public sector.
By integrating predictive AI into government operations, agencies can operate more efficiently, respond more quickly to emerging situations, and serve the public more effectively. For example, predictive AI can:
-
- Predict threats or attacks by analyzing global data, enabling proactive defense measures.
- Anticipate natural disasters, improving emergency preparedness and response strategies
- Forecast disease outbreaks, helping to allocate resources effectively and save lives.
- Prevent failures in critical infrastructure like bridges and electrical grids.
This blog post delves into the essential elements crucial for developing effective predictive AI models in the public sector.
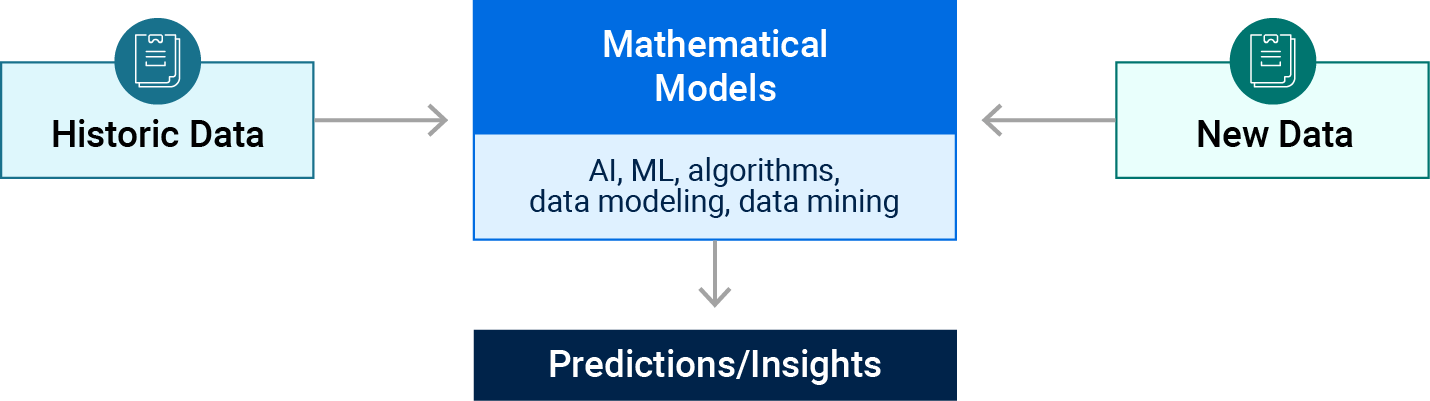
What is Predictive AI?
Predictive AI refers to artificial intelligence systems that use data, statistical algorithms, and machine learning techniques to identify the likelihood of future outcomes or events based on historical and current data. The goal is to go beyond knowing what has happened to provide the best assessment of what will happen in the future. It’s a form of machine learning that helps in making informed decisions by anticipating outcomes.
Predictive AI holds immense potential for government agencies, but at the same time, it has inherent challenges for privacy, accountability, and transparency. Bad data, biased algorithms, and interpretability issues can reduce model reliability and fairness. To effectively harness the power of predictive AI in government, it is imperative to consider and address several key aspects.
Key Considerations for Building Predictive Models
Crafting an effective predictive AI model is an intricate process that demands a strategic blend of technical expertise, domain knowledge, and data acumen.
Here are key considerations to ensure the model’s accuracy, relevance, and operational efficiency.
- Problem Definition and Planning
-
- Problem Definition: Clearly define what you want the AI to predict. Understand the problem domain and determine if it’s classification, regression, clustering, or another type of problem.
- Planning: Design and outline the data collection process, including the sources and types of data needed.
-
- Data Preparation and Exploration
-
-
- Data Collection: Gather a comprehensive dataset that is representative of the problem you are trying to solve. Make sure to include various scenarios and consider the diversity of the data.
 Data Quality and Availability: Implement comprehensive data documentation practices to facilitate understanding and utilization of data assets. Assess the quality of your data. Clean the data by handling missing values, outliers, and errors. Ensure the data is relevant, unbiased, and usable. Establish data quality initiatives and data governance practices to maintain data accuracy, trust, and reliability. Periodically assess and clean data to minimize errors and inconsistencies.
Data Quality and Availability: Implement comprehensive data documentation practices to facilitate understanding and utilization of data assets. Assess the quality of your data. Clean the data by handling missing values, outliers, and errors. Ensure the data is relevant, unbiased, and usable. Establish data quality initiatives and data governance practices to maintain data accuracy, trust, and reliability. Periodically assess and clean data to minimize errors and inconsistencies. - Feature Engineering: Select the most relevant features for your model. Create new features that could improve model performance and remove redundant or irrelevant ones. Ensure all features have a consistent scale. Consider dimensionality reduction while retaining as much information as possible. Leverage domain knowledge to get insights into relevant features that would guide the model development.
-
-
- Model Development and Training
-
- Model Selection: Choose the right algorithms based on the problem type, data size, and complexity. You may need to experiment with several models before finding the most suitable one. Train simple baseline models which provide a benchmark for evaluating the performance of more complex models.
- Training and Testing: Split your data into training and testing sets to evaluate the performance of your model. Use cross-validation to ensure that your model generalizes well.
-
- Model Evaluation
-
- Evaluation Metrics: Determine the appropriate metrics to measure the performance of your model, such as accuracy, precision, recall, F1 score, Receiver Operating Characteristic – Area Under the Curve (ROC-AUC) for classification, or Mean Squared Error) MSE, Root Mean Squared Error (RMSE), Mean Absolute Error (MAE) for regression.
- Algorithmic Objectivity: Evaluate your model to ensure that it contains accurate and comprehensive data.
- Overfitting and Underfitting: Be aware of overfitting, where the model performs well on the training data but poorly on new data. Conversely, underfitting occurs when the model is too simple to capture underlying patterns.
- Explainability and Interpretability: Ensure that your model’s predictions are explainable and can be interpreted by stakeholders. The ability to explain a model’s decisions is critical, especially for sensitive applications. Employ explainable AI techniques (Local Interpretable Model-agnostic Explanations (LIME) and Shapley Additive explanations (SHAP)) to make model decision-making processes transparent and understandable.
- Ethical Considerations: Ensure your AI model complies with regulatory and compliance standards. Implement regular audits and mitigation strategies to address the risk of inaccurate predictions.
- Scalability and Efficiency: Consider if your model can scale to handle larger datasets or streaming data and assess its computational efficiency.

-
- Model Deployment and Monitoring
-
- Deployment: Plan how the model will be deployed. This includes the infrastructure, including AI frameworks, tools, and libraries, how it will be integrated into existing systems, and how it will be monitored and maintained.
- Monitoring and Maintenance: Once deployed, continuously monitor the model for performance decay, and be prepared to retrain it with new data or adjust it as needed.
-
- Iteration and Improvement
-
- Continual Learning: Predictive models can become outdated. Plan for your model to learn continually from new data and adapt to changes in the underlying data distribution.
- User Feedback: Incorporate user feedback to improve the model and make it more responsive to the needs of those who will interact with it.
-
- Documentation and Communication
-
- Documentation: Keep thorough documentation throughout the development process for transparency, which is beneficial for troubleshooting, compliance, and future development.
- Legal and Compliance: Understand and adhere to any legal and regulatory requirements related to the use of AI in your jurisdiction or industry.
- Education and Training: Implement AI literacy training programs to understand and utilize the model, raise awareness about ethical considerations and responsible AI practices, and enhance technical expertise of data scientists, model developers, and other AI practitioners.
-


These considerations are not exhaustive, and the priorities may vary depending on the specific use case and domain. Nonetheless, they provide a broad framework for thinking about the development of a predictive AI model.
For more information about developing predictive models, contact us at info@reisystems.com.
Author:

Ramki Krishnamurthy
Data Analytics Offering Lead
Connect on LinkedIn


